并行程序设计导论期末复习 |
您所在的位置:网站首页 › oracle并行parallel update › 并行程序设计导论期末复习 |
并行程序设计导论期末复习
|
任务并行、数据并行的应用
任务并行
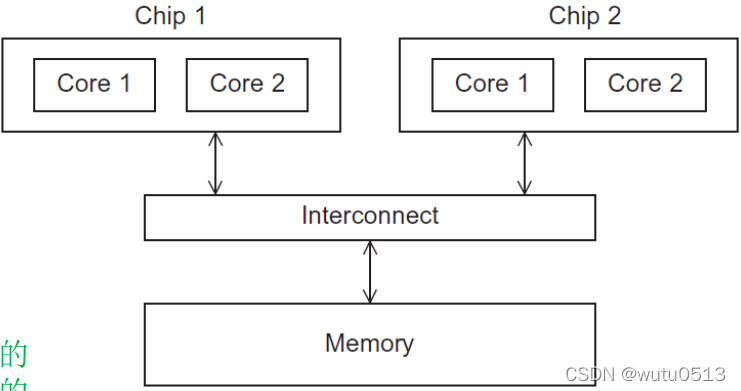
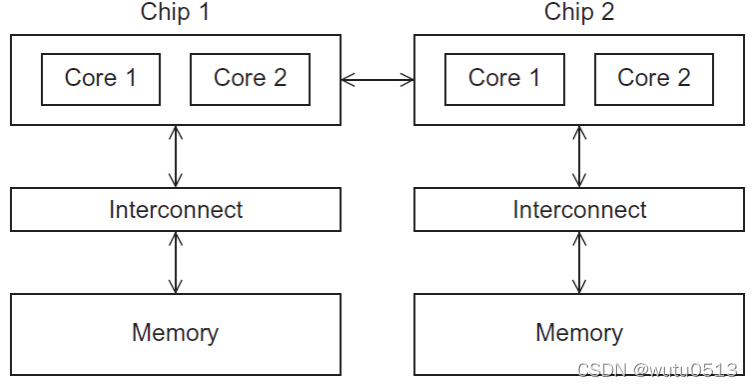
将待解决问题所需要执行的各个任务分配到各个核上执行。 数据并行将待解决问题所需要处理的数据分配给各个核,每个核在分配到的数据集上执行大致相似的操作。 冯诺依曼体系结构的瓶颈及改进,Flynn分类法涉及的几种模型及其特点 冯诺依曼体系结构的瓶颈及改进瓶颈:CPU和主存分离 改进:使用 cache 局部性:在访问完一个内存区域(指令或者数据),程序会在不久的将来(时间局部性)访问邻近的区域(空间局部性)。 Flynn分类法涉及的几种模型及其特点Flynn 分类法的模型 SISD(单指令单数据流) 一次执行一条指令,一次存取一个数据项。 SIMD(单指令多数据流) 通过在处理器之间划分数据而实现的并行性缺点: 所有ALU都需要执行相同的指令,或者保持空闲状态。 在经典设计中,它们还必须同步运行。 ALU不能进行指令存储。 对于大型数据并行问题有效,但对于其它更复杂的并行问题无效。 MISD(多指令单数据流) MIMD(多指令多数据流) 支持多个数据流上同时运行多个指令流 一致内存访问(Uniform Memory Access): 特点:每个核访问内存中任何一个区域的时间都相同 非一致内存访问(Nonuniform Memory Access):
特点: Cache的特点,Cache缺失、Cache命中、Cache一致性及解决方法、伪共享、流水线、多发射缓存的问题 当CPU写数据到cache时,cache中的值可能与主存中的值不一致,有两种解决方法。 写直达(Write-through caches)当CPU向cache写数据时,高速缓存行会立即写入主存中。写回(Write-back caches)将缓存中的数据标记为脏数据。当缓存行(cache line)被内存中的新缓存行替换时,脏缓存行被写入内存。 伪共享两个线程可能访问同一个内存中不同的位置,但是当这两个位置属于同一缓存行时,缓存一致性硬件所表现出来的处理方式就好像这两个线程访问的是内存中的同一位置,如果其中一个线程更新了它所访问的主存地址的值,那么另外一个变量试图读取它要访问的主存地址时,它不得不从主存获取该值。也就是说,硬件强制该线程表现得好像它共享了变量,因此这种情况称为伪共享,这会大大降低共享内存程序的性能。 Cache缺失、Cache命中cache 命中:处理器所要访问的存储块在高速缓存中的现象。 cache 缺失:处理器所要访问的存储块不在高速缓存中的现象。 流水线、多发射指令级并行:通过让多个处理器部件或者功能单元同时执行指令来提高处理器的性能。 流水线:将功能单元分阶段安排。 多发射:让多条指令同时启动。 静态多发:计算单元是在编译时被安排的 动态多发:功能单元是在运行时被安排的 Cache一致性及解决方法Cache一致性:程序员无法控制缓存和何时更新。在多核系统中,各个核的Cache存储相同变量的副本,当一个处理器更新Cache中该变量的副本时,其他处理器应该知道该变量已经更新,其他处理器中Cache的副本也应该更新。这是Cache一致性问题。 解决方法:监听Cache一致性协议、基于目录的Cache一致性协议。 加速比、效率、阿姆达尔定律加速比: S = T 串 行 T 并 行 S= \frac{T_{串行}}{T_{并行}} S=T并行T串行 效率: E = S P = T 串 行 P × T 并 行 E = \frac{S}{P} = \frac{T_{串行}}{P\times T_{并行}} E=PS=P×T并行T串行 阿姆达尔定律(Amdahl’s law):除非所有的串行程序都能够并行,否则无论可用的核的数量再多,加速将非常有限。 例子: 90%的串行程序可以并行化;无论使用多少核p,并行化都是“完美的”; T s e r i a l T_{serial} Tserial= 20 秒; 可并行部分运行时间为: 0.9 × T s e r i a l / p = 18 / p 0.9 \times T_{serial} / p = 18 / p 0.9×Tserial/p=18/p 不可并行化”部分的运行时间为: 0.1 × T s e r i a l = 2 0.1 \times T_{serial} = 2 0.1×Tserial=2 总的运行时间为: T p a r a l l e l = 0.9 × T s e r i a l / p + 0.1 × T s e r i a l = 18 / p + 2 T_{parallel} = 0.9 \times T_{serial} / p + 0.1 \times T_{serial} = 18 / p + 2 Tparallel=0.9×Tserial/p+0.1×Tserial=18/p+2 加速比: S = T s e r i a l 0.9 × T s e r i a l / p + 0.1 × T s e r i a l = 20 18 / p + 2 S =\frac{T_{serial}}{0.9\times T_{serial} / p +0.1\times T_{serial}}=\frac{20}{18/p+2} S=0.9×Tserial/p+0.1×TserialTserial=18/p+220 静态线程、动态线程、伸缩性/可扩展性、数据依赖的识别、任务划分方式及应用 静态线程、动态线程动态线程 主线程通常等待工作请求,当一个请求到达时,它派生出一个工作线程来执行该请求。当工作线程完成任务,就会终止执行再合并到主线程中。这种模式充分利用了系统的资源,因为线程需要的资源只在线程实际运行时使用。 特点:资源的有效使用,但是线程的创建和终止非常耗时。 静态线程 创建线程池并分配任务,但线程不被终止直到被清理。 特点:性能更好,但可能会浪费系统资源。 可扩展性可扩展性 如果一个技术可以处理规模不断增加的问题,那么它就是可扩展的 强可扩展性: 如果在增加进程或线程的数量时,可以维持固定的效率,却不增加问题规模,那么程序被称为强可扩展的 弱可扩展性: 如果在增加进程或线程的数量时,只能以相同倍率增加问题的规模才能使效率值保持不变。 任务划分方式及应用Foster的方法 划分(Partitioning):将要执行的指令和数据按照计算拆分为多个小任务。 这一步的关键在于识别出可以并行执行的任务。通信(Communication):确定前一步所识别出来的任务之间需要执行哪些通信。聚集或聚合(Agglomeration or aggregation):将第一步中确定的任务和通信合并成更大的任务。 例如,如果任务A必须在任务B执行之前执行,那么将它们聚合为单个复合任务可能更为明智。分配(Mapping):将上一步聚合好的任务分配给进程/线程。这一步还要使通信最小化,使得每个进程/ 线程得到的工作量大致均衡(负载均衡)。 |
【本文地址】
今日新闻 |
推荐新闻 |